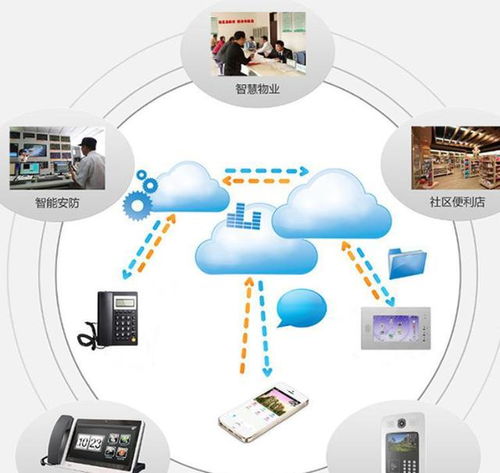
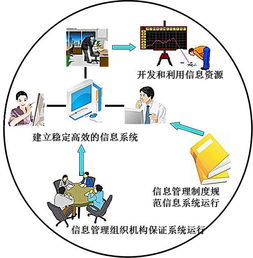
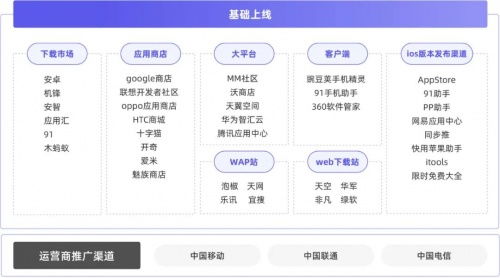
更新時間:2026-06-19 13:50:06
如若轉載,請注明出處:http://www.sujj.cn/product/83.html
PRODUCT
產品列表
更新時間:2026-06-19 20:03:30
更新時間:2026-06-19 07:29:31
更新時間:2026-06-19 12:24:14
更新時間:2026-06-19 00:16:01
更新時間:2026-06-19 20:39:10
更新時間:2026-06-19 03:17:08
更新時間:2026-06-19 05:02:13
更新時間:2026-06-19 18:50:21
更新時間:2026-06-19 01:43:27
地址:陜西省西咸新區空港新城北杜街道辦北杜北街977號
電話:-
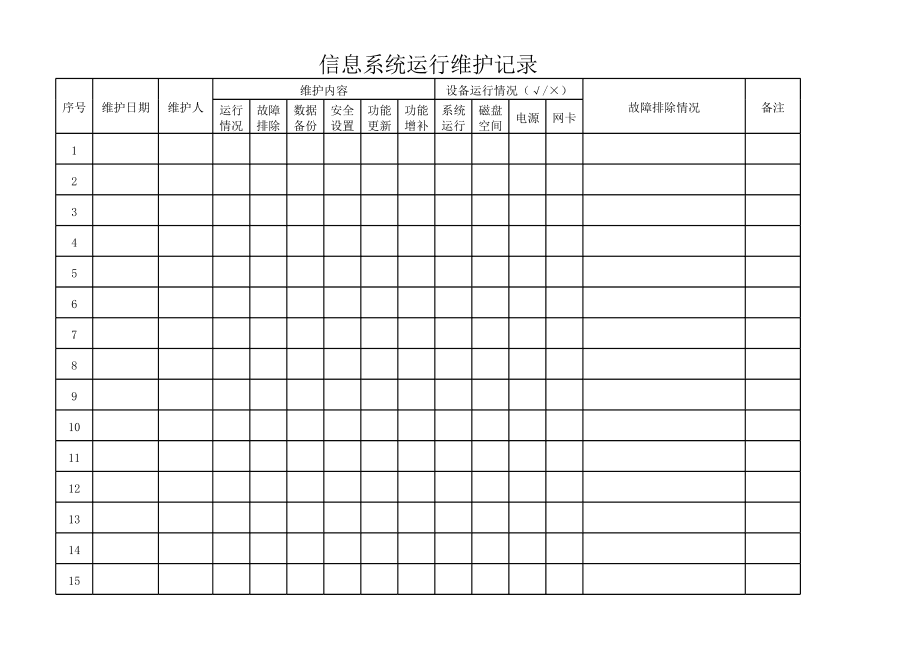
Copyright © 2026 www.sujj.cn 信息系統運行維護服務 陜西解處關融文化傳媒有限公司 信息系統運行維護服務 版權所有 Sitemap
<tfoot id="gmsao"></tfoot>