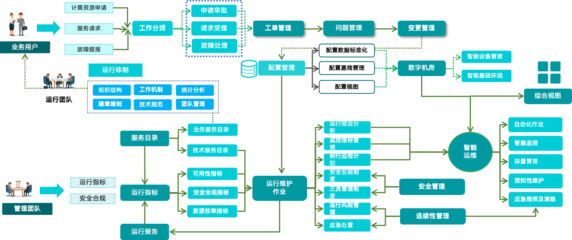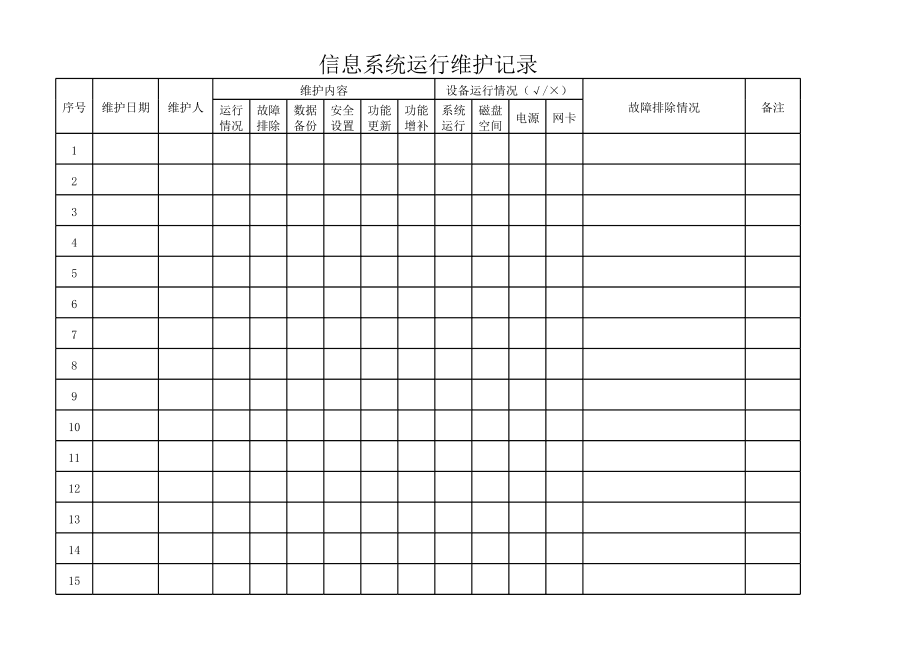
在云計(jì)算技術(shù)如浪潮般席卷全球的今天,信息系統(tǒng)的運(yùn)行維護(hù)服務(wù)正站在一個(gè)歷史性的十字路口。傳統(tǒng)意義上,軟件的終點(diǎn)是“產(chǎn)品”的交付與部署,而如今,在“云”的廣闊架構(gòu)之下,單純的產(chǎn)品思維正日益顯現(xiàn)其局限,一場(chǎng)從“產(chǎn)品末路”到“運(yùn)營(yíng)崛起”的深刻變革,正在運(yùn)維服務(wù)的每一個(gè)環(huán)節(jié)悄然發(fā)生。
一、產(chǎn)品思維的黃昏:從“交付即終點(diǎn)”到“服務(wù)即起點(diǎn)”
過去,信息系統(tǒng),尤其是大型軟件,常被視為一個(gè)需要被“安裝”和“維護(hù)”的“產(chǎn)品”。開發(fā)團(tuán)隊(duì)完成編碼、測(cè)試、打包后,交付給客戶或運(yùn)維團(tuán)隊(duì),其核心任務(wù)便告一段落。后續(xù)的“運(yùn)行維護(hù)”更多地被理解為被動(dòng)響應(yīng)式的故障修復(fù)、補(bǔ)丁更新和性能監(jiān)控。在這種模式下,產(chǎn)品一旦定型,其功能、體驗(yàn)和價(jià)值便相對(duì)固化,迭代緩慢,難以快速響應(yīng)業(yè)務(wù)需求的瞬息萬(wàn)變。可以說,當(dāng)軟件離開開發(fā)環(huán)境,作為“產(chǎn)品”的生命力便開始走向“末路”——它變成了一個(gè)需要被小心呵護(hù),卻難以煥發(fā)新生的靜態(tài)資產(chǎn)。
二、云時(shí)代的基石:運(yùn)維即服務(wù),價(jià)值持續(xù)在線
云計(jì)算的出現(xiàn),徹底改變了這一格局。在云平臺(tái)上,信息系統(tǒng)不再是一個(gè)需要本地部署的“盒子”,而是轉(zhuǎn)變?yōu)橐环N持續(xù)在線、按需獲取的“服務(wù)”。基礎(chǔ)設(shè)施(IaaS)、平臺(tái)(PaaS)乃至軟件本身(SaaS)都成為可彈性伸縮、即時(shí)可用的資源。這一根本性轉(zhuǎn)變,將“運(yùn)行維護(hù)”從后臺(tái)的支撐角色,推向了價(jià)值創(chuàng)造的前臺(tái)。
運(yùn)維的核心職責(zé),從保障“產(chǎn)品”的穩(wěn)定運(yùn)行,升級(jí)為確保“服務(wù)”的連續(xù)性、安全性、高性能與成本優(yōu)化。這要求運(yùn)維工作必須是主動(dòng)的、預(yù)測(cè)性的和業(yè)務(wù)導(dǎo)向的。自動(dòng)化運(yùn)維(DevOps)、智能化監(jiān)控(AIOps)、持續(xù)集成與持續(xù)部署(CI/CD)等理念與實(shí)踐,成為新時(shí)代運(yùn)維的標(biāo)配。運(yùn)維團(tuán)隊(duì)必須深度理解業(yè)務(wù)邏輯,與開發(fā)、產(chǎn)品、市場(chǎng)等部門緊密協(xié)作,共同驅(qū)動(dòng)服務(wù)的迭代與優(yōu)化。
三、運(yùn)營(yíng)的崛起:從“穩(wěn)定守護(hù)者”到“增長(zhǎng)引擎”
正是在“服務(wù)持續(xù)在線”的背景下,“運(yùn)營(yíng)”的價(jià)值被空前放大,并開始與“運(yùn)維”深度融合,甚至引領(lǐng)變革。這里的“運(yùn)營(yíng)”,不僅指?jìng)鹘y(tǒng)的IT運(yùn)營(yíng)(IT Operations),更涵蓋了以用戶為中心、以數(shù)據(jù)為驅(qū)動(dòng)、以業(yè)務(wù)增長(zhǎng)為目標(biāo)的綜合性運(yùn)營(yíng)(Business Operations)。
- 用戶體驗(yàn)運(yùn)營(yíng):運(yùn)維數(shù)據(jù)(如響應(yīng)時(shí)間、錯(cuò)誤率、資源利用率)直接關(guān)聯(lián)用戶滿意度。通過實(shí)時(shí)監(jiān)控與分析,運(yùn)營(yíng)團(tuán)隊(duì)可以快速定位體驗(yàn)瓶頸,驅(qū)動(dòng)產(chǎn)品功能的優(yōu)化,將穩(wěn)定性問題轉(zhuǎn)化為體驗(yàn)提升的機(jī)會(huì)。
- 成本與效率運(yùn)營(yíng):云資源的彈性帶來(lái)了成本優(yōu)化的巨大空間。精細(xì)化運(yùn)營(yíng)需要根據(jù)業(yè)務(wù)負(fù)載動(dòng)態(tài)調(diào)整資源,在保障性能的同時(shí)實(shí)現(xiàn)成本最優(yōu),這直接貢獻(xiàn)于企業(yè)的利潤(rùn)率。
- 數(shù)據(jù)價(jià)值運(yùn)營(yíng):系統(tǒng)運(yùn)行時(shí)產(chǎn)生的海量日志、指標(biāo)數(shù)據(jù)是寶貴的資產(chǎn)。通過運(yùn)營(yíng)分析,可以洞察用戶行為、預(yù)測(cè)業(yè)務(wù)趨勢(shì)、發(fā)現(xiàn)潛在風(fēng)險(xiǎn),為戰(zhàn)略決策提供數(shù)據(jù)支撐,讓信息系統(tǒng)從“成本中心”轉(zhuǎn)變?yōu)椤皵?shù)據(jù)價(jià)值中心”。
- 安全與合規(guī)運(yùn)營(yíng):在云環(huán)境下,安全不再是靜態(tài)的防護(hù)墻,而是需要持續(xù)監(jiān)控、響應(yīng)和迭代的運(yùn)營(yíng)過程。安全運(yùn)營(yíng)(SecOps)與日常運(yùn)維的融合,構(gòu)建起主動(dòng)防御體系。
四、未來(lái)圖景:運(yùn)維與運(yùn)營(yíng)的一體化融合
“產(chǎn)品末路”并非指軟件本身不再重要,而是指那種將軟件視為一次性交付物、運(yùn)維作為售后附庸的舊范式已經(jīng)終結(jié)。在云之下,每一個(gè)信息系統(tǒng)都是一個(gè)持續(xù)演進(jìn)、永不停機(jī)的“數(shù)字生命體”。
未來(lái)的信息系統(tǒng)運(yùn)行維護(hù)服務(wù),將是“運(yùn)維”與“運(yùn)營(yíng)”高度一體化的新形態(tài):
- 組織融合:打破運(yùn)維、開發(fā)、業(yè)務(wù)的壁壘,形成跨職能的融合團(tuán)隊(duì)。
- 流程融合:構(gòu)建從代碼提交到用戶體驗(yàn)反饋的全鏈路自動(dòng)化、數(shù)據(jù)化流程。
- 工具融合:利用統(tǒng)一的平臺(tái)整合監(jiān)控、部署、分析、告警、成本管理等能力。
- 目標(biāo)融合:團(tuán)隊(duì)的共同目標(biāo)不僅是“系統(tǒng)不宕機(jī)”,更是“業(yè)務(wù)持續(xù)增長(zhǎng)”、“用戶體驗(yàn)卓越”和“創(chuàng)新快速落地”。
###
云之下,信息系統(tǒng)的疆域被無(wú)限拓展,其運(yùn)行維護(hù)的內(nèi)涵也發(fā)生了革命性的升華。告別“產(chǎn)品末路”的桎梏,擁抱“運(yùn)營(yíng)崛起”的浪潮,意味著我們必須重新定義運(yùn)維服務(wù)的價(jià)值:它不再是業(yè)務(wù)的成本負(fù)擔(dān),而是驅(qū)動(dòng)數(shù)字化轉(zhuǎn)型、保障業(yè)務(wù)敏捷性、挖掘數(shù)據(jù)金礦的核心競(jìng)爭(zhēng)力。唯有將穩(wěn)定、安全、效率與增長(zhǎng)深度結(jié)合,才能在云時(shí)代為企業(yè)的信息系統(tǒng)賦予真正的生命力與未來(lái)。