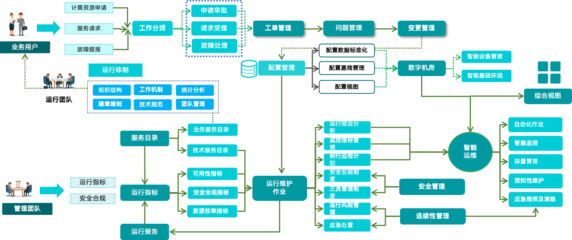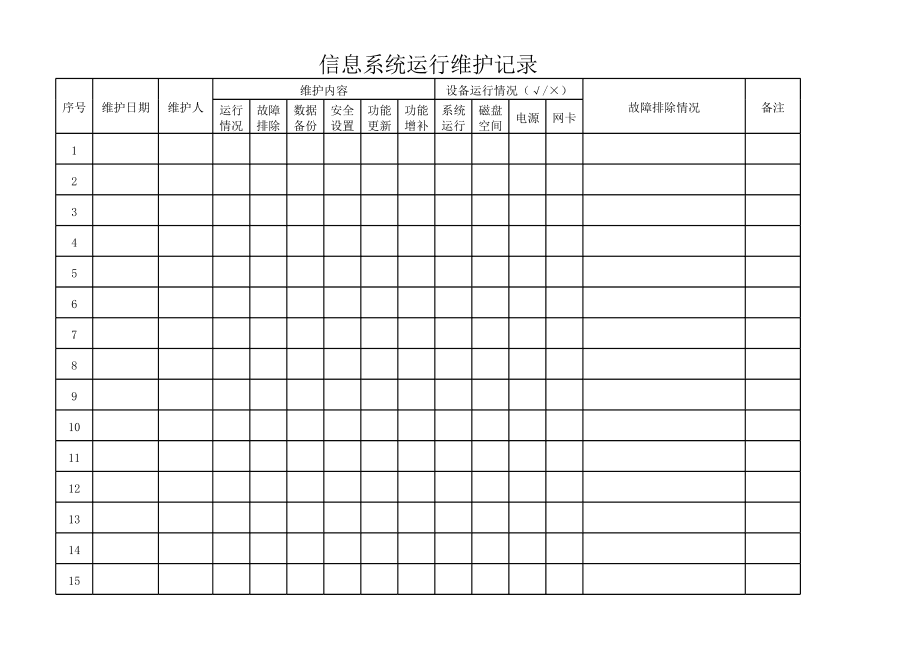
在當(dāng)今快速演進(jìn)的數(shù)字化商業(yè)環(huán)境中,電商平臺(tái)作為復(fù)雜信息系統(tǒng)的典型代表,其架構(gòu)的健壯性、可擴(kuò)展性與可維護(hù)性直接決定了業(yè)務(wù)競(jìng)爭(zhēng)力與運(yùn)營(yíng)效率。從“巨人大哥”這一資深架構(gòu)師的視角出發(fā),深入探討電商微服務(wù)體系中的分層設(shè)計(jì)與領(lǐng)域劃分,并分析其在信息系統(tǒng)運(yùn)行維護(hù)服務(wù)(ITOM/ITSM范疇)中的核心價(jià)值與實(shí)踐要點(diǎn),對(duì)于構(gòu)建可持續(xù)、高效運(yùn)維的現(xiàn)代化電商平臺(tái)至關(guān)重要。
一、 微服務(wù)分層設(shè)計(jì):構(gòu)建清晰、解耦的架構(gòu)基石
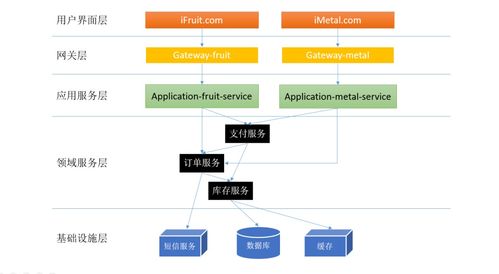
微服務(wù)架構(gòu)的核心優(yōu)勢(shì)在于通過(guò)服務(wù)的細(xì)粒度拆分實(shí)現(xiàn)解耦與獨(dú)立部署。在電商體系中,合理的分層是保障這一優(yōu)勢(shì)的基礎(chǔ)。通常,一個(gè)成熟的電商微服務(wù)分層模型包含:
- 接入層(API Gateway層):作為系統(tǒng)對(duì)外的統(tǒng)一入口,負(fù)責(zé)路由、認(rèn)證、限流、監(jiān)控等橫切關(guān)注點(diǎn)。例如,將用戶(hù)請(qǐng)求分發(fā)至商品查詢(xún)、訂單創(chuàng)建或支付處理等不同服務(wù)。
- 業(yè)務(wù)服務(wù)層(核心領(lǐng)域?qū)樱?/strong>:這是系統(tǒng)的核心,根據(jù)領(lǐng)域驅(qū)動(dòng)設(shè)計(jì)(DDD)思想劃分的各個(gè)微服務(wù)所在層。例如,獨(dú)立的“用戶(hù)中心服務(wù)”、“商品目錄服務(wù)”、“庫(kù)存服務(wù)”、“訂單服務(wù)”、“支付服務(wù)”、“營(yíng)銷(xiāo)促銷(xiāo)服務(wù)”等。每個(gè)服務(wù)封裝獨(dú)立的業(yè)務(wù)能力與數(shù)據(jù),通過(guò)API進(jìn)行協(xié)作。
- 支撐服務(wù)層(公共服務(wù)層):提供被業(yè)務(wù)服務(wù)層公共依賴(lài)的基礎(chǔ)能力,如“消息隊(duì)列服務(wù)”、“緩存服務(wù)”、“文件存儲(chǔ)服務(wù)”、“搜索引擎服務(wù)”、“配置中心”、“日志服務(wù)”等。這些服務(wù)的穩(wěn)定性是業(yè)務(wù)服務(wù)可靠運(yùn)行的保障。
- 數(shù)據(jù)持久層:每個(gè)微服務(wù)原則上擁有獨(dú)立的數(shù)據(jù)庫(kù)(或Schema),實(shí)現(xiàn)數(shù)據(jù)自治。這要求仔細(xì)設(shè)計(jì)數(shù)據(jù)一致性方案(如Saga模式、事件驅(qū)動(dòng)等)。
分層設(shè)計(jì)使得系統(tǒng)結(jié)構(gòu)清晰,職責(zé)明確,為運(yùn)行維護(hù)服務(wù)中的監(jiān)控、故障定位、容量規(guī)劃與彈性伸縮提供了天然的拓?fù)鋱D。
二、 領(lǐng)域劃分:基于業(yè)務(wù)邊界的服務(wù)切割藝術(shù)
領(lǐng)域劃分是微服務(wù)設(shè)計(jì)的難點(diǎn)與精髓,劃分不當(dāng)會(huì)導(dǎo)致服務(wù)間耦合過(guò)緊,淪為“分布式單體”。巨人大哥強(qiáng)調(diào),應(yīng)遵循以下原則進(jìn)行領(lǐng)域劃分:
- 基于業(yè)務(wù)能力:而非技術(shù)層級(jí)。例如,“訂單履約”是一個(gè)完整的業(yè)務(wù)能力,可能涉及訂單狀態(tài)管理、庫(kù)存扣減、物流觸發(fā)等,需仔細(xì)界定其邊界,避免與“庫(kù)存管理”、“物流跟蹤”服務(wù)產(chǎn)生不合理的依賴(lài)循環(huán)。
- 高內(nèi)聚、低耦合:將變更原因相同、功能緊密相關(guān)的對(duì)象放在同一個(gè)服務(wù)邊界內(nèi)。例如,商品的上下架、價(jià)格、庫(kù)存(銷(xiāo)售層庫(kù)存)變更通常關(guān)聯(lián)緊密,可歸屬于“商品服務(wù)”;而倉(cāng)庫(kù)的實(shí)物庫(kù)存管理、盤(pán)點(diǎn)、調(diào)撥可能屬于獨(dú)立的“倉(cāng)儲(chǔ)WMS服務(wù)”。
- 考慮團(tuán)隊(duì)結(jié)構(gòu)(康威定律):服務(wù)劃分應(yīng)盡量與產(chǎn)品、研發(fā)團(tuán)隊(duì)的職責(zé)邊界對(duì)齊,以提升協(xié)作效率。
- 漸進(jìn)式演進(jìn):初期不必過(guò)度拆分,可從較粗粒度的服務(wù)開(kāi)始,隨著業(yè)務(wù)復(fù)雜度和團(tuán)隊(duì)規(guī)模增長(zhǎng),再逐步拆分。關(guān)鍵在于定義清晰的接口契約。
一個(gè)典型的電商核心領(lǐng)域劃分包括:用戶(hù)域、商品域、交易域(訂單/購(gòu)物車(chē))、支付域、營(yíng)銷(xiāo)域、物流域、庫(kù)存域、評(píng)價(jià)/客服域等。每個(gè)域可進(jìn)一步拆分為多個(gè)微服務(wù)。
三、 分層與領(lǐng)域劃分在信息系統(tǒng)運(yùn)行維護(hù)服務(wù)中的核心價(jià)值
精心的架構(gòu)設(shè)計(jì)直接賦能運(yùn)行維護(hù)服務(wù)的效率與質(zhì)量:
- 監(jiān)控與可觀測(cè)性:清晰的層級(jí)和領(lǐng)域劃分,允許運(yùn)維團(tuán)隊(duì)建立層次化的監(jiān)控儀表盤(pán)。從網(wǎng)關(guān)層(流量、延遲、錯(cuò)誤率)到各業(yè)務(wù)服務(wù)層(服務(wù)健康度、業(yè)務(wù)指標(biāo)如下單成功率)、到底層基礎(chǔ)設(shè)施(數(shù)據(jù)庫(kù)連接池、緩存命中率)。故障可以快速被定界到具體層級(jí)或領(lǐng)域服務(wù)。
- 故障隔離與彈性:服務(wù)間的解耦意味著單個(gè)服務(wù)(如“促銷(xiāo)計(jì)算服務(wù)”)的故障或性能瓶頸,可以通過(guò)熔斷、降級(jí)等機(jī)制進(jìn)行隔離,避免級(jí)聯(lián)故障影響核心交易鏈路(如下單)。運(yùn)維可以針對(duì)不同服務(wù)制定差異化的SLA和容災(zāi)策略。
- 變更管理與發(fā)布:獨(dú)立部署的微服務(wù)使得灰度發(fā)布、藍(lán)綠部署等策略可以按服務(wù)維度執(zhí)行,風(fēng)險(xiǎn)可控。運(yùn)維流程可以對(duì)接不同領(lǐng)域的發(fā)布節(jié)奏,例如商品服務(wù)的發(fā)布頻率可能遠(yuǎn)高于支付服務(wù)。
- 容量管理與成本優(yōu)化:不同領(lǐng)域的業(yè)務(wù)負(fù)載模式不同(如“秒殺營(yíng)銷(xiāo)服務(wù)”峰值尖刺,“用戶(hù)服務(wù)”相對(duì)平穩(wěn))。運(yùn)維可以根據(jù)各服務(wù)的實(shí)際壓力,進(jìn)行更精細(xì)化的資源調(diào)度、彈性伸縮和成本核算。
- 問(wèn)題排查與根因分析:當(dāng)出現(xiàn)跨服務(wù)業(yè)務(wù)問(wèn)題時(shí)(如“訂單支付成功但未扣庫(kù)存”),基于領(lǐng)域事件鏈路的追蹤(通過(guò)分布式鏈路追蹤系統(tǒng))可以清晰地還原調(diào)用路徑,結(jié)合各服務(wù)日志,快速定位是哪個(gè)領(lǐng)域服務(wù)的邏輯或數(shù)據(jù)出現(xiàn)了不一致。
四、 給運(yùn)維團(tuán)隊(duì)的實(shí)踐建議
巨人大哥對(duì)運(yùn)維團(tuán)隊(duì)提出以下建議,以更好地適配和管理分層、分領(lǐng)域的微服務(wù)架構(gòu):
- 擁抱DevOps與GitOps文化:運(yùn)維需要深度參與服務(wù)設(shè)計(jì)評(píng)審,理解領(lǐng)域邊界和依賴(lài)關(guān)系。基礎(chǔ)設(shè)施及部署應(yīng)代碼化、自動(dòng)化。
- 構(gòu)建統(tǒng)一的運(yùn)維平臺(tái):集成服務(wù)注冊(cè)發(fā)現(xiàn)、配置管理、監(jiān)控告警、日志聚合、鏈路追蹤、持續(xù)部署等功能,提供以“服務(wù)”為中心的統(tǒng)一視圖。
- 制定領(lǐng)域服務(wù)SLA標(biāo)準(zhǔn):與業(yè)務(wù)方共同定義不同領(lǐng)域服務(wù)的核心指標(biāo)與可用性要求,作為容量規(guī)劃與故障應(yīng)急的基準(zhǔn)。
- 加強(qiáng)混沌工程實(shí)踐:主動(dòng)在測(cè)試環(huán)境注入故障,驗(yàn)證服務(wù)的容錯(cuò)能力和故障隔離效果,持續(xù)加固架構(gòu)的韌性。
- 建立領(lǐng)域?qū)<覅f(xié)同機(jī)制:復(fù)雜問(wèn)題排查時(shí),運(yùn)維需能快速聯(lián)動(dòng)對(duì)應(yīng)業(yè)務(wù)領(lǐng)域的開(kāi)發(fā)專(zhuān)家,共同解決問(wèn)題。
###
總而言之,電商微服務(wù)體系的分層設(shè)計(jì)與領(lǐng)域劃分,不僅是技術(shù)架構(gòu)的藍(lán)圖,更是高效信息系統(tǒng)運(yùn)行維護(hù)服務(wù)的基石。它從設(shè)計(jì)源頭降低了系統(tǒng)的復(fù)雜性,為運(yùn)維的監(jiān)控、應(yīng)急、變更和優(yōu)化工作提供了清晰的地圖和可控的單元。巨人大哥認(rèn)為,優(yōu)秀的架構(gòu)與卓越的運(yùn)維能力相輔相成,共同支撐著電商業(yè)務(wù)在激烈市場(chǎng)競(jìng)爭(zhēng)中的敏捷、穩(wěn)定與持續(xù)增長(zhǎng)。運(yùn)維團(tuán)隊(duì)從“資源管理者”向“服務(wù)可靠性賦能者”的角色轉(zhuǎn)變,正始于對(duì)這套架構(gòu)理念的深刻理解與實(shí)踐。