在數字化轉型浪潮席卷各行各業的今天,企業營銷正面臨著前所未有的機遇與挑戰。信息的爆炸式增長、消費者行為的快速變遷、市場競爭的日益激烈,都對企業營銷的敏捷性、精準性和效率提出了更高要求。正是在此背景下,一種深度融合信息技術與商業智慧的新型服務應運而生——以信息系統運行維護為核心的智慧經營服務,正悄然成為企業營銷的得力助手,讓復雜變簡單,讓繁瑣變高效。
一、智慧經營:定義營銷新范式
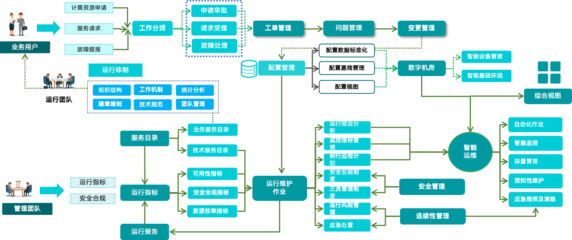
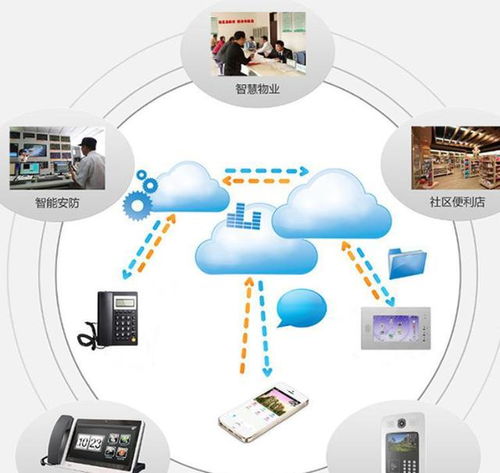
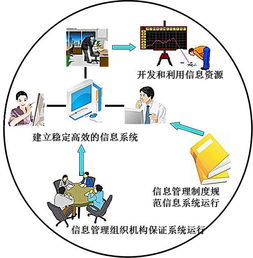
智慧經營并非一個抽象的概念,它依托于先進的信息技術,特別是穩定、安全、高效的信息系統運行維護服務,將數據轉化為洞察,將流程優化為動能。傳統的企業營銷往往依賴經驗決策和分散的推廣活動,而智慧經營則通過集成的信息系統,實現從市場分析、客戶畫像、策略制定、內容分發到效果評估的全鏈路數字化管理。其核心在于,通過持續、專業的系統運維保障,確保營銷數據流的暢通無阻與計算資源的可靠供給,為智能決策提供堅實底座。
二、信息系統運行維護:智慧營銷的“隱形引擎”
許多人將信息系統運維簡單理解為“修電腦、管服務器”,實則不然。在現代智慧經營體系中,專業的運行維護服務扮演著至關重要的“隱形引擎”角色。
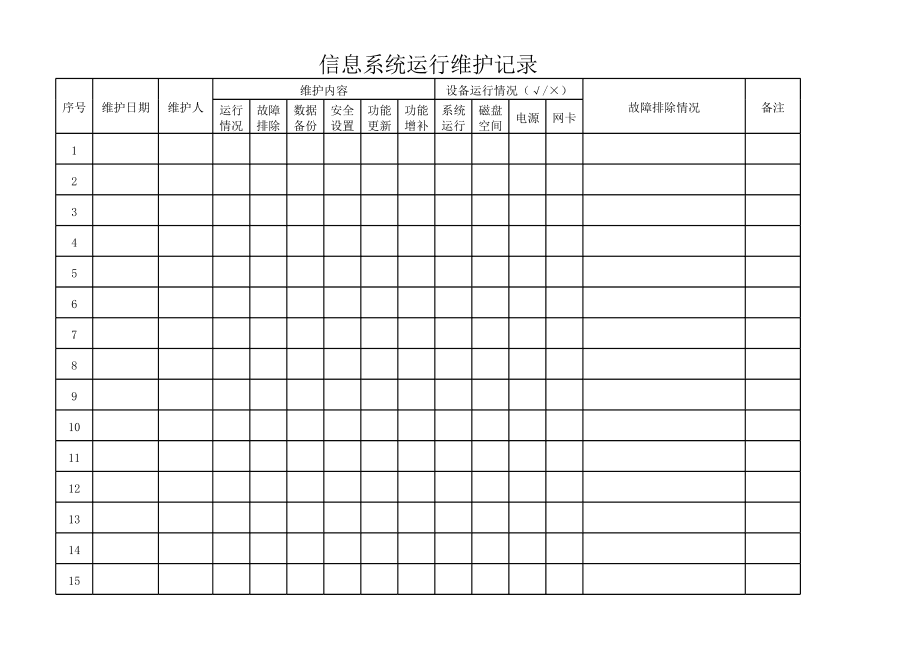
- 保障系統穩定與連續性:任何營銷活動,無論是大型促銷、直播帶貨還是日常的客戶關系管理,都離不開后臺系統的支持。7x24小時的監控、預警與快速故障響應,確保營銷平臺永不掉線,避免因技術問題導致的客戶流失與商機錯失。
- 優化性能與用戶體驗:運維團隊通過性能調優、負載均衡等技術手段,保障營銷系統在高并發訪問下的流暢運行。快速的頁面加載、穩定的交易流程,直接提升了客戶滿意度和轉化率。
- 筑牢數據安全防線:客戶數據是營銷的核心資產。運維服務通過嚴格的訪問控制、數據加密、備份容災及安全漏洞修補,構建全方位的數據安全護城河,確保企業合規經營,贏得客戶信任。
- 賦能數據分析與迭代:運維不僅保證系統“跑得穩”,還通過維護數據管道、數據倉庫的清潔與可用性,為營銷數據分析、用戶行為追蹤提供高質量“燃料”,使A/B測試、精準投放、效果歸因等精細化營銷成為可能。
三、智慧經營服務如何讓營銷“更簡單”
“更簡單”并非意味著功能簡化,而是指通過技術賦能,將企業從復雜的技術管理和低效的流程中解放出來,更專注于營銷戰略與創意本身。
- 化繁為簡的統一平臺:智慧經營服務往往提供一個集成化的平臺或解決方案,將CRM、SCRM、營銷自動化、數據分析等工具無縫整合。企業無需在不同系統間切換、對接,在一個界面內即可完成多維度營銷管理,極大降低了操作復雜度和學習成本。
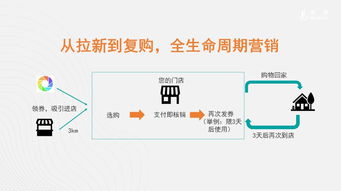
- 數據驅動的自動與智能:基于運維保障下的穩定數據流,系統可以自動執行客戶細分、個性化內容推送、營銷旅程觸發等任務。AI算法的引入,更能實現潛客評分、需求預測、預算優化等智能決策,將營銷人員從重復勞動中解放,聚焦于高價值創造。
- 敏捷響應與快速迭代:可靠的運維基礎使得營銷系統能夠快速部署新功能、新活動頁面,支持營銷團隊進行小步快跑式的測試與優化。市場變化時,企業能第一時間調整策略并上線實施,抓住轉瞬即逝的商機。
- 降低總體擁有成本(TCO):專業的運維服務通常采用訂閱或服務外包模式,企業無需投入巨額資金自建運維團隊和基礎設施,即可享受專家級的技術支持。這將固定成本轉化為可變成本,使企業,尤其是中小企業,能夠以更輕的資產、更靈活的投入開展高水平的數字化營銷。
四、展望:邁向深度融合的未來
隨著云計算、人工智能、物聯網技術的進一步成熟,智慧經營與信息系統運維服務的結合將更加緊密和深入。運維本身也將更加智能化(AIOps),實現從被動響應到主動預測的跨越。企業營銷將在一個高度自動化、智能化、安全可靠的技術環境中進行,真正做到“技術無形,營銷有道”。
在數字經濟時代,營銷的競爭在某種程度上已演變為技術支撐能力的競爭。選擇以專業信息系統運行維護服務為基石的智慧經營解決方案,就是為企業營銷安裝上穩定而強大的“數字心臟”。它讓技術后臺堅實如磐石,讓營銷前臺靈動如流水,最終賦能企業在復雜市場中游刃有余,實現可持續的增長。智慧經營,正讓高效、精準、簡單的營銷,成為所有企業觸手可及的現實。